
人工智能語言模型的發展日新月異,Inception Labs 最新推出的 Mercury 被譽為市場上首款商業級「擴散式大型語言模型」(dLLM)。該模型以其高效能與低成本備受矚目。以下將介紹 Mercury 的特點,以及它與 ChatGPT 和 DeepSeek 的區別。
Mercury 簡介及其獨特性
Mercury 是由 Inception Labs 開發的一款 AI 語言模型,其核心優勢在於採用「擴散技術」(Diffusion),有別於傳統的「自迴歸」(Autoregressive)方法。這一技術使其在生成速度、運算成本及應用效率上表現優異,特別適用於需快速響應的場景。
Inception Labs 背景
Inception Labs 是一家總部位於美國的人工智能技術公司,團隊由來自 史丹福大學(Stanford)、加州大學洛杉磯分校(UCLA) 及 康乃爾大學(Cornell) 的研究人員與工程師組成。其核心成員包括史丹福大學教授 Stefano Ermon,他曾參與早期影像擴散模型的研究,對 Midjourney 和 Sora 等技術產生深遠影響。該公司致力於通過擴散技術提升語言模型性能,其研究成果曾在 NeurIPS、ICML、ICLR 等國際會議上發表,技術實力廣受認可。
Mercury 3 大特點
Mercury 在性能上有以下顯著特徵:
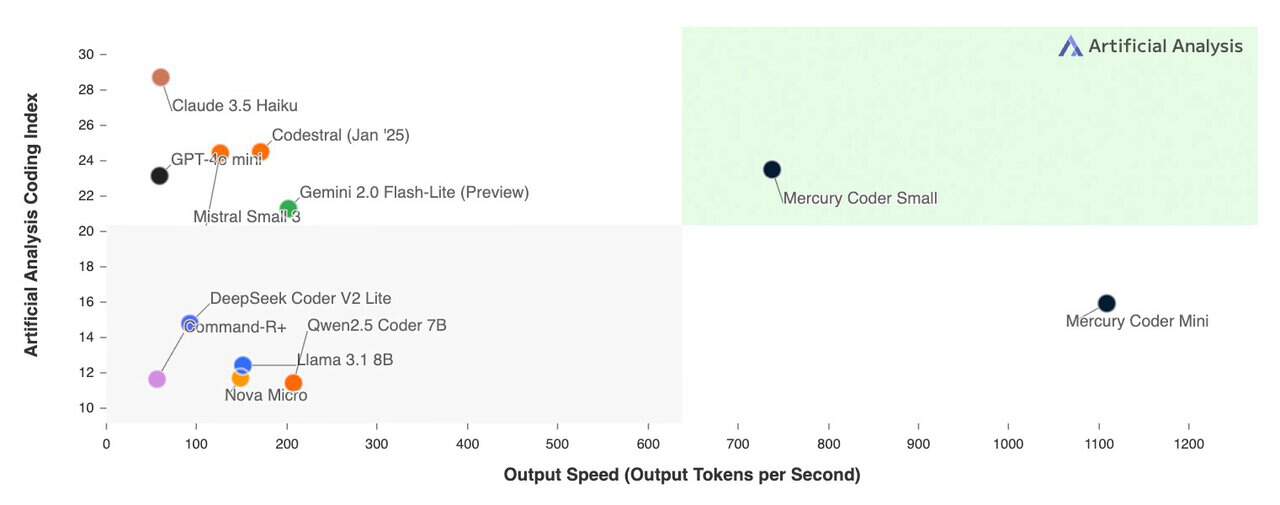
高效生成:Mercury Coder Mini 每秒可生成超過 1000 Token,Coder Small 達 750 Token,較大多數模型快 5 – 10 倍。測試顯示,其生成回應僅需 6 秒,而 ChatGPT 耗時 36 秒。
低成本:相較傳統模型,其運算資源需求減少,成本降低 10 倍。
應用價值:在程式碼生成領域表現出色,於 Copilot Arena 測試中,Mercury Coder Mini 位列第二,超越 GPT-4o Mini 和 Gemini-1.5-Flash,深受開發者青睞。
生成速度比較:
擴散模型 vs 自迴歸模型
理解 Mercury 的高效能,需從其技術原理與傳統模型的差異入手。
自迴歸模型(如 ChatGPT 與 DeepSeek)
-運作方式:按順序逐詞生成文字,每個 Token 需依賴前文計算。
-局限:生成速度受限,即使優化後的模型最高僅達每秒 200 Token,如 GPT-4o 僅為 60 – 70 Token,前沿模型更低於 50 Token。
-特性:準確性高但成本較高(如 ChatGPT),或速度較快但精確度稍低(如 DeepSeek)。
擴散模型(如 Mercury)
-運作方式:從隨機雜訊出發,逐步精煉至完整文字,並通過 Transformer 模型並行處理多個 Token。
-優勢:生成速度顯著提升,Mercury Coder Mini 在 NVIDIA H100 上達每秒 1000+ Token,較其他模型快 5 – 20 倍,同時具備更強的推理與錯誤修正能力。
-特性:兼顧速度與品質,且成本效益高。

Mercury 與 ChatGPT、DeepSeek 對比
以下表格整理 Mercury 與 ChatGPT、DeepSeek 在技術、性能與應用上的差異:

ChatGPT:高精度但成本高昂
技術:基於自迴歸的 GPT 架構。
特點:擅長對話與文章生成,輸出自然且準確。
速度:平均每秒 50 – 200 Token(如 GPT-4o Mini)。
成本:訓練與運行費用高昂,GPT-4 估計耗資數億美元。
適用場景:適合追求高品質輸出的應用。
DeepSeek:速度快且成本低
技術:自迴歸結合 MoE(混合專家)技術。
特點:專注程式碼與數學問題,生成速度優於 ChatGPT,成本低(訓練約數百萬美元)。
速度:高於 ChatGPT,每秒約 300 – 500 Token,遠不及 Mercury。
成本:提供開源免費版本,小型模型可於個人電腦運行。
適用場景:適合注重成本效益的技術應用。
Mercury:高效與實惠並重
技術:採用擴散模型(dLLM)。
特點:生成速度領先(Coder Mini 每秒 1000+ Token,Coder Small 750 Token),性能媲美 GPT-4o Mini 和 Claude 3.5 Haiku,快 10 倍,HumanEval 測試得分達 88 與 90。
速度:較 ChatGPT 和 DeepSeek 快 5 – 10 倍。
成本:成本降低 10 倍,無需特殊硬體。
適用場景:適合需要高速程式碼生成的應用。

架設成本:企業應用分析
Mercury 的部署成本具競爭力,無需高端硬體(NVIDIA H100 即可),並提供 API 訪問 與 本地部署 選項,支援 SFT 和 RLHF 微調。以下為成本對比:

企業部署 Mercury 時,一張 NVIDIA H100(約 24 – 32 萬港幣)搭配伺服器(約 8 – 16 萬港幣),初始投入約 40 – 50 萬港幣,每月維護費用約數千至一萬港幣。API 模式按使用量計費,預估每百萬 Token 數港幣。相較之下,DeepSeek 小模型(7B、14B)僅需 RTX 4090(約 1 – 2 萬港幣)即可運行,成本低廉,但其大型模型(671B)需 18 – 20 張 H100,總成本達 500 – 800 萬港幣。Mercury 以單張 H100 實現高效能,對追求速度的中小企業更具優勢,API 模式則提供靈活的低成本選擇。
優勢與限制
優勢
高效能:Coder Mini 每秒 1000+ Token,普通硬體即可運行。
智能表現:具備生成修正與推理能力,結構化輸出更優。
開發者認可:在 Copilot Arena 中速度第一,品質第二。
靈活性:支援 API 與本地部署。
限制
應用範圍:以程式碼生成為主,對話與文章生成不如 ChatGPT。
技術新穎:擴散技術尚待長期穩定性驗證。
型號選擇:目前僅有 Coder 與 Mini,不如 DeepSeek 多樣。
使用方式與版本
Mercury 為商業產品,提供 API 與本地部署選項,同時在 Playground(chat.inceptionlabs.ai) 開放免費試用,可觀察文字從雜訊到清晰的生成過程。目前版本包括 Mercury Coder(每秒 750 Token)與 Coder Mini(每秒 1000+ Token),聊天模型仍在封閉測試中,型號選擇相對有限。
總結:潛力與展望
Mercury 以擴散技術實現了語言模型的速度突破,其每秒 1000+ Token 的生成能力,結合低成本特性,為程式碼生成領域帶來顯著進展。相較於 ChatGPT 的高精度與 DeepSeek 的低成本,Mercury 在高效能與實用性間找到平衡點。Inception Labs 的技術背景為其發展奠定基礎,未來若能擴展至對話領域,並提升穩定性,或將對現有市場格局產生衝擊。對科技愛好者而言,Mercury 是值得關注的創新技術,其後續發展令人期待。
分享到 :
最新影片
