Google 系列企業 DeepMind 開發的 AlphaGo 圍棋 AI 系統,在人機對戰贏了中國棋手柯潔之後退役。不過 DeepMind 已經準備好用全新技術製作的「AlphaGo Zero」AI 系統,最大的進化是它毋須學習人類對弈,僅透過自我強化學習的演算法,就能學成精通的圍棋技藝。

以往的 AlphaGo 學習圍棋,使用了大量人類圍棋對局的資料進行學習,另外再加上自我對弈以加強學習效果。但今次 DeepMind 在科學雜誌《Nature》就發表了題為《Mastering the game of Go without human knowledge》(毋須人類智識就能掌握圍棋)的論文。當中提到了進化版的「AlphaGo Zero」人工智能系統,可以只單靠自我學習來達到掌握圍棋技藝。
在全新技術當中,AlphaGo Zero 神經網絡從一塊連圍棋規則也不知道的「白板」開始,技術人員再將這個網絡跟搜尋演算法結合,然後就開始了自我學習。AI 人工智能系統不斷進行自我對弈,把自己的下棋方法加以學習、改進,不斷增強下棋的判定。它只從一塊「白板」開始學習,用了 3 天的時間,就達到了他的上兩代「AlphaGo Lee」(擊敗棋手李世乭的系統),而只利用了 21 日的時間,就達到了他的上一代「AlphaGo Master」(擊敗柯潔的系統)相同的水準。

從開始就能自我學習的 AlphaGo Zero,厲害之處除了靠自我學習就得到了人類長久以來累積的圍棋策略經驗之外,更獲得了一些人類棋手未知的策略技術。AlphaGo Zero 系統只用了 40 日,就成為了世界最強的圍棋棋手。
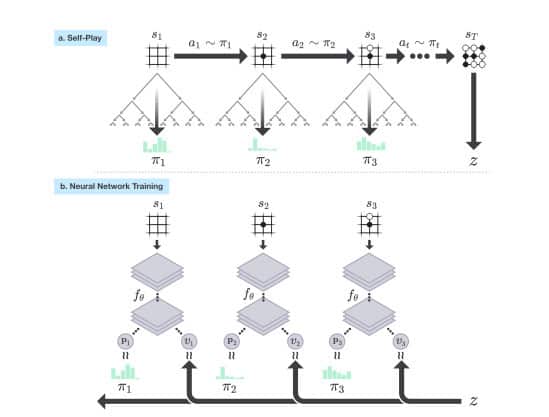
▲AlphaGo Zero的自我學習流程
深度學習需要有大量資料輔助,例如以前 AlphaGo 需要的對局資料,有時候資料的成本高昂,而且知識有時也未必輕易得到。AlphaGo Zero 這項技術突破,日後可利用於解決人類未曾認識的重大挑戰。
資料來源:YouTube, Google, NPR
分享到 :
最新影片
