
中國初創公司 DeepSeek 近日悄悄發佈新一代大型語言模型 DeepSeek-V3-0324,這款模型不但只以開源方式釋出,更能在 Apple 的 Mac Studio 裝置上流暢運行,有用家就實測能夠每秒處理超過 20 個 token,打破過往需依賴大型數據中心的傳統觀念。今次技術突破讓 AI 模型的部署方式有望迎來翻天覆地的轉變,並可能對 OpenAI 等現時主導市場的企業構成實質威脅。
DeepSeek-V3-0324 在 3 月 24 日無預警上載至開源平台 Hugging Face,檔案總大小高達 641GB,但並未附帶技術白皮書或宣傳資料。這個來自中國的開發團隊,再次採用低調但具衝擊力的發佈手法,與西方公司預熱數月的傳統市場策略截然不同。

該模型具備 6850 億個參數,屬目前最大型之一,並採用混合專家(Mixture-of-Experts,簡稱 MoE)架構。這個架構會根據不同任務,智能地啟動約 370 億個最合適的參數,取代傳統大型語言模型「全參數激活」的方式,大幅減少運算需求,提升效率。研究人員指出,這種設計不但節省硬件資源,還可令運行速度顯著加快。
另外,DeepSeek-V3-0324 加入兩項關鍵技術創新:「多頭潛在注意力(Multi-Head Latent Attention,簡稱 MLA)」和「多 Token 預測(Multi-Token Prediction,簡稱 MTP)」。MLA 令模型在處理長文本時,能更準確掌握上下文脈絡;而 MTP 則讓模型每輪運算能產生多於一個 token,輸出速度可比傳統方法提高接近 80%。
有測試者在配備 M3 Ultra 晶片及 512GB 記憶體的 Mac Studio 上,使用 4-bit 精簡版本的 DeepSeek-V3 模型,成功達到每秒超過 20 個 token 的生成速度。該版本的模型檔案縮小至 352GB,令一般消費級裝置亦有能力執行這類頂尖模型,無需高功耗的多張 Nvidia GPU 加持。
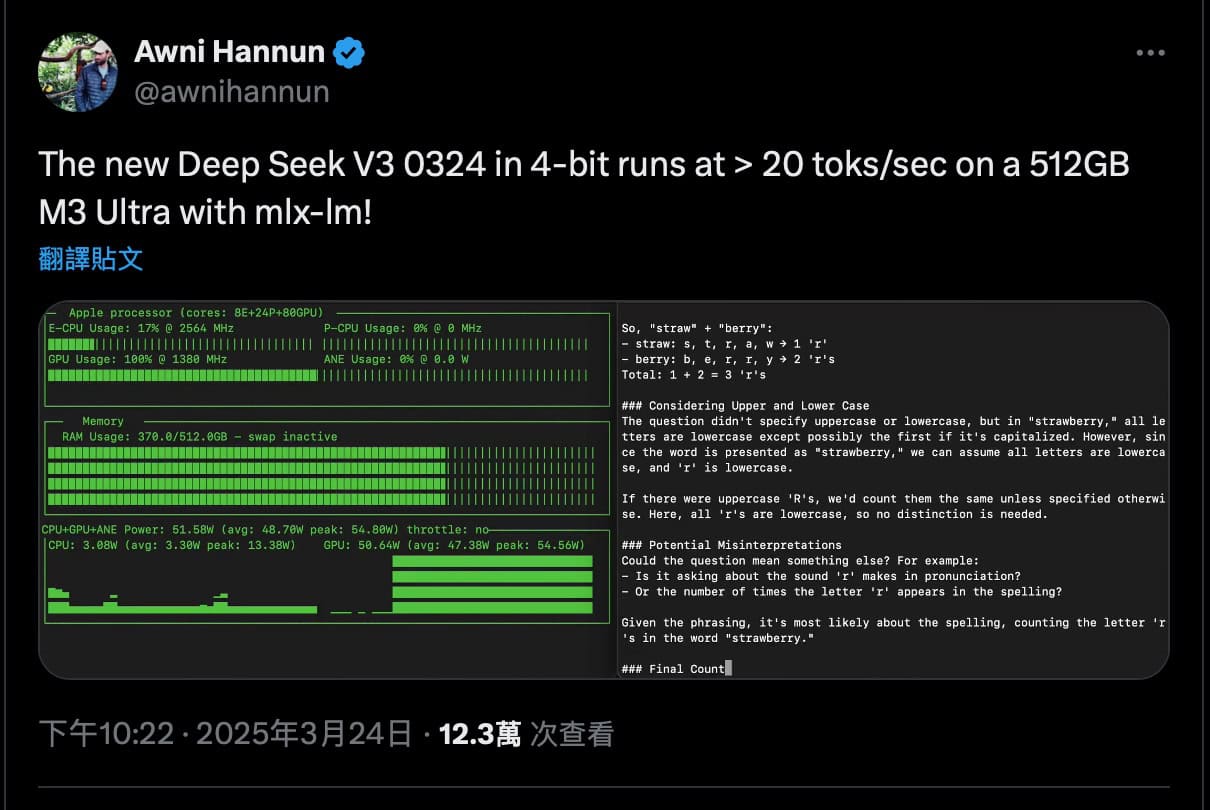
有 AI 研究人員表示,在內部測試中,DeepSeek-V3-0324 在多項測試項目中均明顯領先前一代模型,甚至壓倒目前商用市場上備受推崇的 Claude Sonnet 3.5。與後者不同,DeepSeek 提供的是免費、可商業使用的模型權重,進一步打破高端 AI 模型高門檻的既有格局。
DeepSeek 的出現及其發展策略,不但重新定義大型語言模型的部署方式,也對 AI 產業的競爭格局構成挑戰。若未來該模型繼續維持開放與高效的特質,有可能令更多開發者與企業從 OpenAI、Anthropic 等企業的付費平台轉向開源解決方案。
The new Deep Seek V3 0324 in 4-bit runs at > 20 toks/sec on a 512GB M3 Ultra with mlx-lm! pic.twitter.com/wFVrFCxGS6
— Awni Hannun (@awnihannun) March 24, 2025
分享到 :
最新影片
