人的耳朵其實有一種特技,可以聽見只想聽到的聲音,在嘈吵的環境中,集中接收自己想聽到的資訊,耳朵自自然然會屏敝其他噪音。而近日 Google AI 亦發展出相類似的系統,在嘈吵環境下只專注一個人的聲音,對於日後語音辨識、即時語音翻譯來說都有很大幫助。
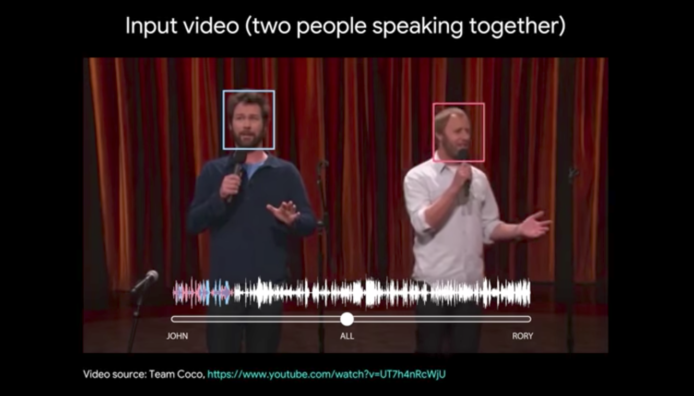
以往的電腦語音系統,無法收聽單獨人聲的音訊,如果同時間有兩個人說話,就無法進行語音辨識。Google AI 發表「Looking to Listen」技術,利用深度學習製作視聽模型,從混聲、嘈雜的聲音中,分離出單一音訊,增強特定人聲並降低環境嘈音。Looking to Listen 更能夠透過偵測視訊內容,以辨別說話者的特徵,例如咀形、聲音來源,辨識現在正在說話的人,以協助判斷影片中人的聲音。系統會通過音訊分離模型,輸出個別的聲音資料。
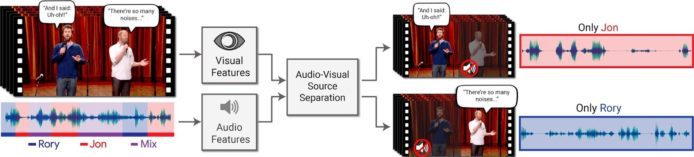
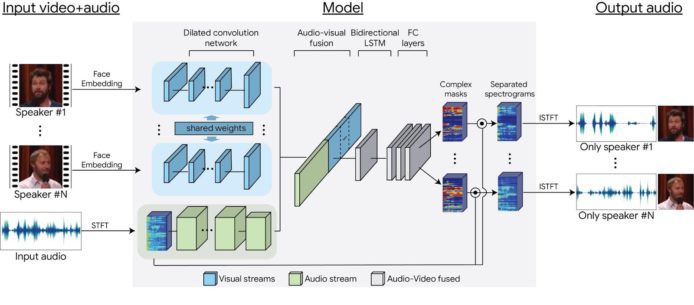
Google 結集了超過 10 萬段演講影片中的 2,000 小時純淨的聲音,把這些聲音混合、結合其他資料庫,作為深度學習視聽模型的學習材料。未來這個技術可用於自動字幕的生成製作,有利於語音辨識系統運作,為會議或嘈雜環境下錄得的影片作後期處理等等。
資料來源:Google
分享到 :
最新影片
